(ほぼ)AWS初心者が Amplify & Chalice ハンズオンに参加した話
概要
AWS loft Tokyoで定期開催されるハンズオンイベント「 AWS Amplify & Chalice ハンズオン #03 〜怠惰なプログラマ向け お手軽アプリ開発手法〜 1 」に参加してきた話。ちなみにAWS自体ほぼ初心者のワタシです。 イベントの雰囲気をざっくりあげると以下です。
- ハンズオンの2コース( Amplify と chalice の自由選択)どちらを取り組むか挙手すると Amplify:chalice = 7:3 くらいだった
- 教材を提供しながらマイペースに取り組む(コピペで十分動くがコードの中身で気になることも聴いて欲しい)
- サポータはつくが今回は dev support スポット(AWS Loft Tokyo内)に一人以上常駐する形式
AWSアカウントをもっていれば開発環境(電源, wifiなど)の整った AWS Loft Tokyo を無料利用できるので、そのきっかけにするイベントなのではとも感じました。
Amplify とは
サーバーレスなバックエンドをセットアップするための CLI、フロントエンドで利用できる UI コンポーネント、CI/CD やホスティングのためのコンソールを含む Web およびモバイルアプリ開発のためのフレームワークです。
用意されるハンズオンコース
- チャット機能の実装
- AI 機能の実装
- イベント・属性分析機能の実装
- Web Pushの実装 [new]
モバイルアプリ構築(作成、設定、構築)からバックエンドのプロビジョニングにより管理を統合したフレームワークです。つまり、Amplify さえ使いこなせればモバイルアプリをリリースできてしまいます。 参加した回では、ServiceWorker コンポーネントを利用してブラウザ通知の実装コースが新しく追加されていました(WebPush の実装)。 Amplify framework に興味のある方はコチラを試してみてください。 自分はイベントに参加するまで知らなかったので次回はこちらを挑戦してみようかな(やるとは言っていない)。 AWS AmplifyFramework
chalice とは
Amazon API Gateway と AWS Lambda を使ったサーバーレスアプリケーションを素早く開発しデプロイできるサーバーレスフレームワークです。
本題です。 API gateway と lambda を使ったサーバレスアプリケーションをシンプルに構築して RESTful APIを管理したい、が使い所です。そんな chalice は、意外と会場で挑戦者が少なかったようだったので少しでも広まって欲しい気持ちから取り上げてみます。本記事でちょっとでも良さが伝わればウレシイです。 ちなみに、AWSオンラインセミナーでも紹介されていてslideshareに公開されています。
かわいさ
- 自動で
app.py等が生成される(Flask ライクな最小構成) $chalice deployだけで高速デプロイ- API gateway で組み込みオーソライザーを手軽に使える -> 直感的なインターフェース
準備
$ pip3 install virtualenv $ virtualenv ~/.virtualenvs/chalice-handson $ source ~/.virtualenvs/chalice-handson/bin/activate
Install
$ pip3 install chalice
※念の為AWSの認証情報が正しいか設定ファイルを確認しておきましょう( ~/.aws/credentialsと~/.aws/config )。
プロジェクト作成
chalice は new-project で新規プロジェクト作成できます。
$ chalice new-project helloworld
コマンドを実行するとディレクトリ配下に Python のマイクロフレームワークである flask の構成 + .chalice という、まさに最小構成ができているはずです。
デプロイ
これをしたいがために chalice を触っていると言っても過言はありません(?)。
$ chalice deploy
バーン!...
本当にこれだけでデプロイできているの... curl してみましょう。
$ curl https://qxea58oupc.execute-api.us-west-2.amazonaws.com/api/
{"hello": "world"}
これで API Gateway と Lambdaファンクションがコマンドひとつでデプロイされてしまう。簡単。しかも速い。
URLパラメータの取得
ここからURLパスに指定した値で欲しい情報を返す処理を追加しています。
app.py のデコレータ @app.route() に パラメータを返す View, getparam 関数を追加します。
from chalice import Chalice app = Chalice(app_name='helloworld') CITIES_TO_STATE = { 'seattle': 'WA', 'portland': 'OR', } @app.route('/') def index(): return {'chalice': 'handson'} @app.route('/cities/{city}') def state_of_city(city): return {'state': CITIES_TO_STATE[city]}
追加できたらデプロイしてhttpコマンドを叩いてみます。
$ chalice deploy
$ http https://hoge.execute-api.us-east-1.amazonaws.com/api/cities/seattle
{
"state": "WA"
}
$ http https://hoge.execute-api.ap-northeast-1.amazonaws.com/api/cities/portland
{
"state": "OR"
}
エラーメッセージとレスポンスのカスタマイズ
デフォルトでは無効になっているのデバックモードを有効にします。
from chalice import Chalice app = Chalice(app_name='helloworld') app.debug = True
再びこのAPIにリクエストを投げてみると以下のようになります。
(chalice-handson) ➜ helloworld http https://hoge.execute-api.ap-northeast-1.amazonaws.com/api/cities/sanfrancisco
HTTP/1.1 500 Internal Server Error
Connection: keep-alive
Content-Length: 280
Content-Type: text/plain
Date: Thu, 28 Nov 2019 11:31:56 GMT
Via: 1.1 8afc3f299389b6df1d38dfe8a5520639.cloudfront.net (CloudFront)
X-Amz-Cf-Id: HWm2BSvWfbycfBqxY-rCbxzFgHzgYRAwlCY3tmEH2UzdZ_lTDGMUbQ==
X-Amz-Cf-Pop: NRT53
X-Amzn-Trace-Id: Root=1-5ddfb02b-99e9ea18bd0b2148b0be4448;Sampled=0
X-Cache: Error from cloudfront
x-amz-apigw-id: D3h24GbYNjMFhmg=
x-amzn-RequestId: 9cf0fcfb-0461-4987-b1b2-1e31544a9c36
Traceback (most recent call last):
File "/var/task/chalice/app.py", line 1104, in _get_view_function_response
response = view_function(**function_args)
File "/var/task/app.py", line 22, in state_of_city
return {'state': CITIES_TO_STATE[city]}
KeyError: 'sanfrancisco'
ちゃんと失敗してトレース情報を出力してくれました。実行URLのパラメータはドキュメント通りsanfranciscoで試していますが、それ以外でもやってみましょう。
今回は 500 Internal Server Error を返してみましたが、 400 Bad Request なら BadRequestError をインポートするなどその他の例外キャッチもクラスとResponseオブジェクトでカスタマイズが可能です。
from chalice import BadRequestError @app.route('/cities/{city}') def state_of_city(city): try: return {'state': CITIES_TO_STATE[city]} except KeyError: raise BadRequestError("Unknown city '%s', valid choices are: %s" % ( city, ', '.join(CITIES_TO_STATE.keys())))
レスポンスコードとエラー
- BadRequestError - return a status code of 400
- UnauthorizedError - return a status code of 401
- ForbiddenError - return a status code of 403
- NotFoundError - return a status code of 404
- ConflictError - return a status code of 409
- UnprocessableEntityError - return a status code of 422
- TooManyRequestsError - return a status code of 429
- ChaliceViewError - return a status code of 500
このステップでは
例外を丸めすぎたり握りつぶしたりせず、ちゃんと適切な情報を返しましょうね。
という印象的な一文がありました。明日の自分のためにもしっかり例外をキャッチするようにしたいですね。
リクエストのメタデータ(header や body)を取得
app.current_request は Viewでリクエストのメタデータを参照するオブジェクトです。
@app.route('/introspect') def introspect(): return app.current_request.to_dict()
こちらも http コマンドを実行して帰ってくる情報を確認してみてください。 ここでは出力が多いため割愛します。
CORS のサポート
CORS(Cross-Origin Resource Sharing) 対応はどのようなwebエンジニアにも必要です。特にSPAのような構成のアプリケーションなどが利用シーンです。chalice ではパラメータの追加だけで対応が可能です。
from chalice import CORSConfig cors_config = CORSConfig( allow_origin='https://foo.example.com', allow_headers=['X-Special-Header'], max_age=600, expose_headers=['X-Special-Header'], allow_credentials=True ) @app.route('/custom_cors', methods=['GET'], cors=cors_config) def supports_custom_cors(): return {'cors': True}
cors に True を渡すだけで実現できます。
定期処理を行う Lambda ファンクション
最後に、様々な Lambdaファンクションの定義の中から定期処理 schedule を app.py に実装します。
マネジメントコンソールから CloudWatch Logs で起動されたことを確認してみます。
from chalice import Chalice, Rate from datetime import datetime @app.schedule(Rate(1, unit=Rate.MINUTES)) def periodic_task(event): launch_time = datetime.now().strftime("%Y/%m/%d %H:%M:%S") print('function_launched:' + launch_time) # ここでlogに吐く return {"function_launched": launch_time}
いつものようにデプロイします。
(chalice-handson) ➜ chalice deploy Creating deployment package. Updating policy for IAM role: helloworld-dev Creating lambda function: helloworld-dev-periodic_task Updating lambda function: helloworld-dev Updating rest API Resources deployed: - Lambda ARN: arn:aws:lambda:ap-northeast-1:hoge:function:helloworld-dev-periodic_task - Lambda ARN: arn:aws:lambda:ap-northeast-1:hoge:function:helloworld-dev - Rest API URL: https://hoge.execute-api.ap-northeast-1.amazonaws.com/api/
このあとにLambdaマネジメントコンソールには webAPI の関数 helloworld-dev とは別の helloworld-dev-periodic_task が追加されています。
今回は定期実行を確認したのでモニタリング画面も確認しましょう。
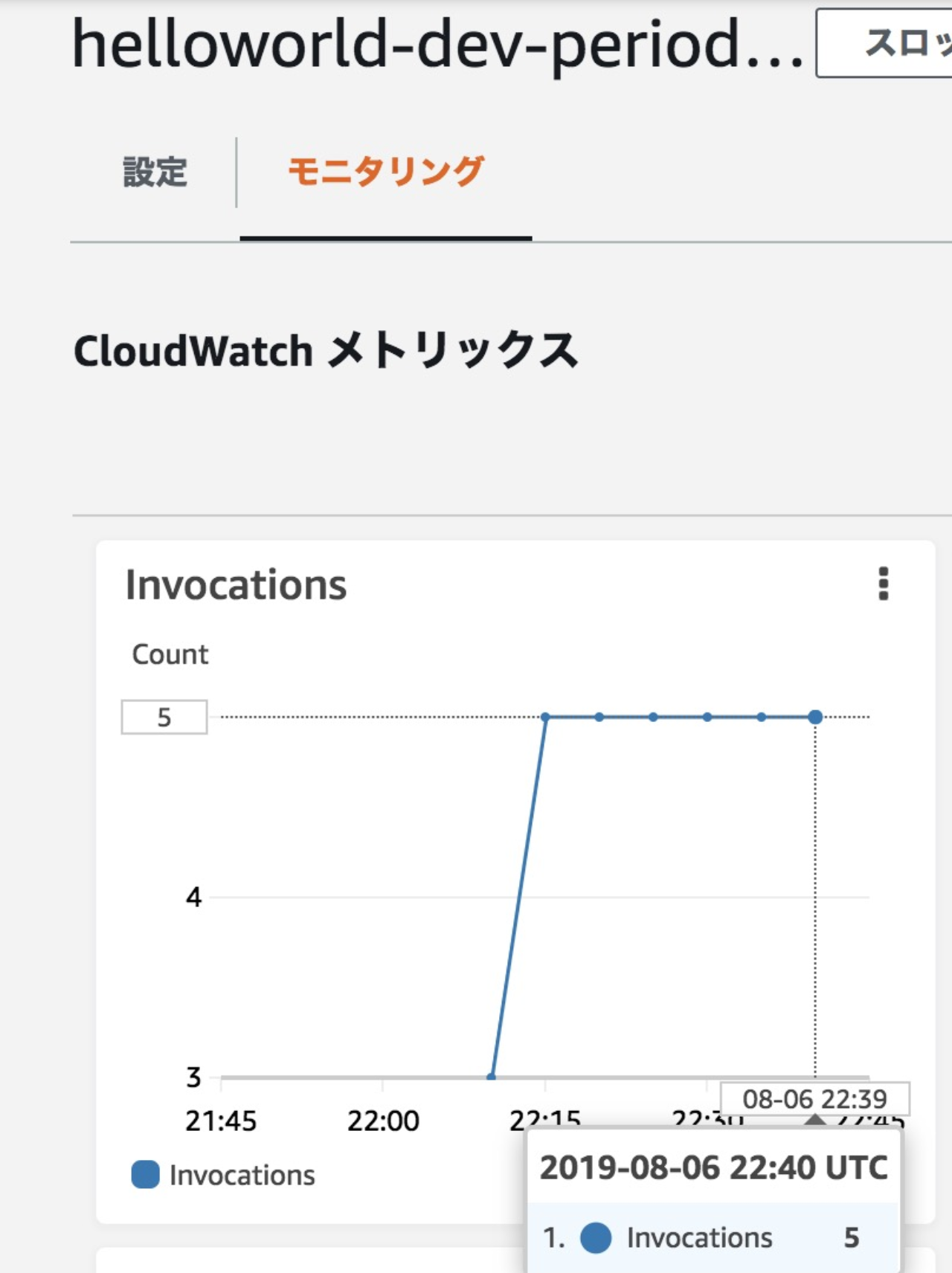
print した 'function_launched:' + launch_time はロググループ一覧から確認できます。(このメトリックスグラフ上の「ログの表示」から遷移しても確認することができました。)
実行ログに function_launched:yyyy/mm/dd HH:mm:ss の文字列が出力されているはずです。
感想とか
だいたいの動作がめちゃ速い。。お茶を飲んでいる場合ではない。 今回参加して得たことは、 chaliice の使い方もそうですがAWSが初めての人でもわかるほど丁寧なドキュメントとサポートがあったので体系理解の点でも助かりました。 自分は最近仕事で Restful な API や Lmbdaファンクションを利用した Slack bot 開発をしている際にAWSまわりは初めて触っていたので、かなり参考になりましたし、なによりハンズオンのレベルがちょうどよくAWSはじめるゾイ、な人がまず取り組める内容だと思います。
宣伝
Opt technologiesではハンズオンはもちろん各種イベントを開催しています、ご興味ある方は是非参加お待ちしています! https://opt.connpass.com/
開発合宿でGCPのautoML(ベータ版)を触ってみた話
弊社では毎年開発合宿(去年の様子)でエンジニアがYATTEIKIを発揮します。最近はビジネスサイド参加者が増えていて活発っぽい。時代はAIバブルですが Google の Cloud autoMLを触ってみたら楽にAIな開発ができたので、機械学習なんもわからんマンでもできる実装手順を紹介します。
はじめに
〜ランチ中〜
弊社データサイエンティスト「kaggle のachievement機能みたいに社員を格付けしたい」
私「どうして」
弊社データサイエンティスト「人類は評価されると嬉しいから」
私「天才」
アイデア
コンペ資料など社内知見共有をするwebアプリケーション(Quarry1)を利用し、アップロードした資料につく「いいね」「お気に入り」「ダウンロード数」「カテゴリ」「タグ」情報から以下の機能を考えました。
AutoMLによる投稿時のカテゴリ(投稿種別)の自動付与- 投稿のレコメンド
- ユーザーのランク付けによる投稿動機付け

↑をもとに作った↓
※ステージング環境のデータベースとはいえ(コンプライアンス的に)完全アウトなのでモザイク

主なポイントは
- 採石場という意味のQuarryにちなんでユーザランクは
石ころ<<<<<サファイヤまで - recommendsカラムにアイテム(資料)を3つサジェスト表示
の2点です。アプリケーションの構成技術スタックは flask + Vue.js で実装しました。

今回は2番目のサジェスト機能で利用した AutoML Text Classification にフォーカスします。
AutoMLって
冒頭でも紹介しましたが、現在(2019/12)Google Cloud Platform がβ版で公開している機械学習APIです。
今回利用した Cloud Natural Language API だけでなく、画像や翻訳など各分野のAPIが展開されています。

今回は、資料のファイル名とそれに紐づくカテゴリデータ(タグもある)をもとにレコメンドモデルを生成したいので、Natural Language をクリックします。 すると自然言語系のプロダクト一覧がダッシュボード画面に表示されます。 カテゴリ分類を行う機械学習モデルを作成する AutoML Text Classification を利用します。

前処理
機械学習といえば前処理。前処理を制する者は人類を制す。それは言いすぎかも。 普通に jupyter notebook (今後Jupyter labに移行予定らしい2)でQuarryのDBから対象データを抽出していきます。
必要なライブラリ等諸々。
import csv import os import pandas as pd import mysql.connector from flask import Blueprint, request, jsonify
ステージングのDBと接続します。
# DB connection func. def get_connection(): conn = mysql.connector.connect( host='quarry-staging.hoge.ap-northeast-1.rds.amazonaws.com', port=3306, user='hogest', password='sayhoge', database='db_name', ) return conn
mysql-connector-python(sqlight3でも良い)を使って欲しいテーブルやカラムをSQLで execute していきます(一例)。
db_name = Blueprint('db_name', __name__, url_prefix='/api/db_name') # メッセージリスト def list_message_query(): """ "id", "user_id", "message_div", "scope_div", "title", "message", "url_flg", "link_url", "link_url_kind", "thumbnail_url", "update_user_id", "status", "created", "updated", """ conn = get_connection() cur = conn.cursor() cur.execute(f""" select id, user_id, title, message, updated, created from messages where status = 0 """) return cur.fetchall()
あとはリストを作って map 関数とlambda式で要素を変更しながら各テーブルごと同様の加工をします。
massage_list = list(map(lambda x: { "id": x[0], "title": x[2], "message": x[3] }, list_message_query()))
ラベルに使う category_id(カテゴリ番号) を抽出します。
df_raw_cid = pd.DataFrame(category_list, columns=['id', 'category_id'])
はじめはtitle(資料名)とmessage(資料のコメント)をくっつけて学習しようとした日もありました。
body_str = add_categoryId['title']+add_categoryId['message'] # cid を Series -> df に変換 df_body_str = pd.DataFrame(body_str, columns = ['title_message']) type(df_body_str)
コメントの文字列に改行や特殊文字など扱いにくい文字列がたくさんあるとわかったので、やっぱり message カラムいらない、、、みたいな紆余曲折。
drop_col_message = ['message'] df = add_categoryId.drop(drop_col_message, axis=1)
結局必要なカラムだけをとった df_title と df_cid を concat してCSVに吐きました。Dataframeで作成したので勝手についてしまうindexは index=False することを忘れないでください、AutoMLのデータセットに不要なようです。
dataset_tc = pd.concat([df_title, df_cid], axis=1) dataset_tc.dropna(how='any') dataset.to_csv('data/dataset_tc.csv', index=False)
データセットのインポート

- 該当するファイルのアップロード(今回は jupyter notebook でデータ整形をしたので「パソコンからCSVファイルをアップロード」した)。

...なんとこれだけで学習モデルの作成がスタートします。
考察
トレーニング結果
以下のようなデータセットが作成されました。

対象データのアイテム数とカテゴリラベルなど詳細は以下です。 ちなみに学習が終わるまで2時間くらいかかりました。モデル生成に時間はかかりますが、あとは学習済みのモデルをAPIで使うだけなので、毎回この時間がかかるわけではありません。

| アイテム数 | |
|---|---|
| 全てのアイテム | 9416 |
| ラベル付き | 8151 |
| ラベルなし | 1267 |
| トレーニング | 6522 |
| 検証 | 816 |
| テスト | 813 |
評価
トレーニングが終了したら生成モデルの評価を行います。分類精度として適合率(Precision)と再現率(Recall)の2つを指標とします。お互いにトレードオフの関係であるため、ケースによってどちらを優先するべきか判定する材料となるわけです。 アイテムの嗜好に適合させたい今回のケースはレコメンドエンジンとして評価したいので、適合率を優先します。反対に、よく例に出てくる癌予測のケースでは再現率を優先して病気の見逃しをできるだけ減らすことに注視します。
$$ Precision = \frac{TP}{FP+TP} $$
$$ Recall = \frac{TP}{FN+TP} $$
陽性(True)と予測した結果によって、実際に陽性だった結果を真陽性(True-Positive)、違った結果を偽陽性(False-Positive)と定義しそれぞれの指標をします。陰性(Negative)の場合も同様に真陰性(True-Negative)と偽陰性(False-Negative)と表します。

また、正解ラベルと実際の予測結果を行列で表現する混同行列(Confusion matrix)も評価指標となります。 各行(列)で高い予測割合が右斜め下にクロスしていればよいモデルと判断できます。
適合率,再現率(Precision, Recall)の結果
 閾値(Confidence thresholdの調整バーで設定)の時点で適合率が高く性能としては良さそうです。
閾値(Confidence thresholdの調整バーで設定)の時点で適合率が高く性能としては良さそうです。
混同行列(Confusion matrix)の結果
 ラベル5,10はもともとアイテム数が少なく割合が低くなってしまいました。アイテム数が0のラベル6はしっかりはじかれていることがわかります。
ラベル5,10はもともとアイテム数が少なく割合が低くなってしまいました。アイテム数が0のラベル6はしっかりはじかれていることがわかります。
カテゴリラベルごとの結果
| ラベル | アイテム数 | 適合率(%) | 再現率(%) |
|---|---|---|---|
| 1.媒体資料 | 660 | 68.57 | 36.36 |
| 2.提案資料 | 2701 | 89.95 | 66.3 |
| 3.施策・事例共有 | 3058 | 84.36 | 75.82 |
| 4.機能・テクニック | 363 | 100 | 19.44 |
| 5.業務効率化・改善 | 214 | 100 | 0 |
| 6.タスク・スケジューリング管理 | 0 | null | null |
| 7.業界・市場・競合調査 | 554 | 84.09 | 67.27 |
| 8.セミナー・勉強会 | 473 | 58.62 | 36.17 |
| 9.連絡 | 92 | 100 | 44.44 |
| 10.教本・基礎 | 36 | 100 | 0 |
AutoML Text Classification は、設定したラベルごとのF値(しかもTP,FP,TN,FNごとに)の結果を出してくれています、すごい(KONAMI)。

最もスコアが高いラベル2の中でも、正しく予測できなかったアイテムが一覧で確認できるので何が原因だったのか考察することができます。
例えば、提案資料カテゴリの偽陰性一覧にあがっているアイテムで資料名に「提案資料」と入っているものが複数観測できました。これは「提案資料」の前後に別カテゴリに分類されそうな「施策」や他カテゴリに多い社名(固有名詞)が入っており、文脈による単語間の類似度計算かなにかがされていたりして(要出典)、「提案」とあっても分類されないケースもあるようです。
テストと使用
ダッシュボード上でGCPから新たなデータをこのモデルに判定させることもできます。

Cloud Natural Language は API なので当然アプリケーションコードに組み込むことで推薦機能を実装できます。
まずは、
$ curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json" \ https://automl.googleapis.com/v1beta1/projects/391983214514/locations/us-central1/models/TCN1234567790hogehoge:predict \ -d @request.json
と curl を叩くと、
{ "payload": { "textSnippet": { "content": "YOUR_SOURCE_CONTENT", "mime_type": "text/plain" } } }
request.json が返ってきます。
GDC fileなら以下。
{ "payload": { "document": { "input_config": { "gcs_source": { "input_uris": "YOUR_GCS_FILE_URI" } } } } }
Pythonの場合、 predict.py として以下のように書くことができます。
import sys <200b> from google.api_core.client_options import ClientOptions from google.cloud import automl_v1beta1 from google.cloud.automl_v1beta1.proto import service_pb2 <200b> def inline_text_payload(file_path): with open(file_path, 'rb') as ff: content = ff.read() return {'text_snippet': {'content': content, 'mime_type': 'text/plain'} } <200b> def pdf_payload(file_path): return {'document': {'input_config': {'gcs_source': {'input_uris': [file_path] } } } } <200b> def get_prediction(file_path, model_name): options = ClientOptions(api_endpoint='automl.googleapis.com') prediction_client = automl_v1beta1.PredictionServiceClient(client_options=options) <200b> payload = inline_text_payload(file_path) # Uncomment the following line (and comment the above line) if want to predict on PDFs. # payload = pdf_payload(file_path) <200b> params = {} request = prediction_client.predict(model_name, payload, params) return request # waits until request is returned <200b> if __name__ == '__main__': file_path = sys.argv[1] model_name = sys.argv[2] <200b> print get_prediction(content, model_name)
あとは
$ python predict.py 'YOUR_SOURCE_FILE' projects/391983214514/locations/us-central1/models/TCN1234566789hogehoge
と実行して確かめてみましょう。カンターン。
まとめ
院生時代、マシンを1週間並列処理(物理)したり論文に実験結果を載せようとscikit-learnでゴリゴリコード書いて混同行列とか作ったり、毎回偽陰性の定義を忘れては確認し(頑張れ)を繰り返していた日々を返して欲しい気もするし返して欲しくない気もしました。
ng-japan2018の備忘録
6月16日に開催されたng-japanの備忘録です.
完全にメモですので,こちらも公式サイトを参照ください.
2018/06/16
angular基調講演
- stability + innovation
$ng update my-cool-library
creating ng-update schematics new generate update add
$ng new my-app
material installs dependencies in packege.json inmport Appmodule
$ng generate
ng add is suppert ng-bootstrap clarity and more...
$ng generate library my-library
Tree shakeble providers
@NgModule({
my-camp
something
...
});

Angular Element
- nasted tree DOM
<mat-tree>
- Form Field
- standard from field
- fill form field
- outline form feild
- Table
- Badge Bottom Sheet
- Angular Matrial
- 130 bug fixes!
Future
- Project Ivy
- ng teamが取り組む新しいprojet
- CDK
https://material.angular.io/cdk
- listbox&combobox
- Datepicker
- Slider
- keeping up to date with Material Design ←awesome
- Virtural Scrolling
<csk-virtural-scroll-viewpoint autosize>
AngularでPWAを進める
翻訳コミッタの人 @studioteatwo mobileよりの機能実装紹介
PWAとは
Progressive Web Apps
PWA = モバイルのWEBページでネイティブアプリのようなUXを提供するためのもの
@angular/pwa
webブラウザとモバイルの一覧性の違い
- add to homescreen
- hedder futterなくなる(mobile)
- 一発でページ表示
- push Notification
- キャッシュリソースはjsonで指定
ng buildで更新
- CacheFirst
- NetworkFirst
- strategy
Feature
- strategy
- まずは"better web app"
- serviceworkerをひっそりbackgroudで動かすだけで恩恵あるらしい
- "Extensibe"
- fullcriant appからmashup
- オフラインアプリの可能性
- PWAでボリュームをカバーできるのでは
- webはネイティブより一段高い中小層
Angular活用実績から、ハマり事例のご紹介
NRIでの大規模プロジェクト開発おいての事例 - 1pxずれてクライアント不具合報告 - AngularJS中心
役割分担の失敗
PL重要度に沿ったフロント人員
迷子の開発者
データの受け渡しどうしよう クライント要件に対する方法が決まっていないせいで設計が進まない
標準化ルール * 処理方式 * 画面遷移パターン * チェックタイミング
→ 誰が作っても同じ構成などのメリット
こんなに?くらいの標準化がみんなのためになる
オフショア開発
- 中国なら100人単位で動員できる
- オフショアの教育
- 対面で伝えられる人数10人
- 声の届く範囲
- 雪だるま式教育法
- Angular研修を作り
- リーダーに持っていってもらう
- 独自チュートリアルに開発の注意点を織り交ぜるなど
メモリリークとの戦い
ex. 車の故障をコールセンタ介してレッカー調達
コールセンタは常にページを立ち上げている 2.5hで1gbの消費メモリ(動作に影響)←ヤバそう
- SPA分割
- 一連の業務完了で再読込
- リークしそうな箇所は局所化
- 共通部品(開発者に使わせない) cf. DOMリーク
標準化と地道なつぶしこみが重要
How we are using Angular + Firebase at NHK leading to the Olympics
Action INDEX shibuya 360° streaming AR(sportをrealtimeで表現) patent power
archtecture peek @NHK
- using Firebase + NHK
- using Cloud Fire Store + NHK
- セキュリティに厳しいNHK →インフラを別のところに持った
- cloud functionを使うことでリモートに操作できる
- リアクティブな構成を保ったままdata bining,jsonをupload
<sFTP> - why Cloud Firebase?
- So many Query
Realtime Data in XR
- VR,AR,MRの違い
- XR
- VR,AR,MRを一つにまとめた言葉
- Latency.
- 20ms over 5G(2ms)標準化されたの?!at 6/15
- webVR
- Everything is Component
- 突然の終了
plantUML componentCSS

必読書
東京はようやく台風が過ぎ去り安堵もつかの間,再び猛暑の予感.
ノマドしようと土曜日に,気になっていたカフェ rompercicci (ロンパーチッチ) さんにふらっと向かいはじめた瞬間に豪雨遭遇.
macを抱えて慌てて中野ブロードウェイに駆け込みおやつを買い込みそそくさと帰宅.かなしい.
まだ行けずにいる rompercicciさんの情報はこちら.
rompercicciさんせっかく台風でもやっていたのになぁ,来週こそ.
オープンしました'∀')ノ まさか今回の台風の正体が「1時間に1回3分間のゲリラ豪雨が降る、の繰り返し」だっとはねえ。さすがにもう降らないですよね? これから先は正常な夏であってほしいと切に願います。蝉時雨につつまれてお待ちしてます!
— rompercicci (@rompercicci) 2018年7月29日
さて,今週のネタは特にないので最近本当の意味で必読書と感じた2冊を紹介します.
エンジニアとして入社してOJTの方から紹介された技術書です,今更紹介するのもおこがましいですしご存知の方がほとんどだと思います.
")
「リーダブルコード」はコードが自分だけ読めればよい,動けば良いという考えを正してくれます.
アプリケーションにおいてとりあえず動く,はむしろ奨励されることですがその前に知っておくべきことがたくさん載っています.
コーディングが行き詰まったときの気分転換代わりによしたかは読んでいます.
")
「コーディングを支える技術」はプログラミングの成り立ちから解説が始まります.
学生時代にはじめてC言語でコードを書いたとき,なぜ for と while 文が同じような役割を持っているか,そもそも使い分けがわからなかったときのモヤモヤを解消してくれました.
どちらも特定のプログラミング言語で構成されていませんし, 大変丁寧な文章で,リーダブルコードはイラストも多く飽きてしまうことはないでしょう.
実は自分の研究室や大学の図書館でよくみかけていたのですが,ここまで早く読んでおくべきだったと後悔すると思いませんでした.
研究内容がニューラルネットワークの理論や統計,解析学を中心に学んでいたのでコーディングは二の次三の次と考えていたのかもしれません.
よくプログラミングのチュートリアルなどで「そういうもの」と飲み込んで,立ち止まる前に新しいものは俯瞰する目的とした進め方をとることがあります.
しかし,リファクタリングを後回しにしてしまいなかなか取り組まないときがあるように,正しい理由と使い方はなにを学ぶにしても土台で,後回しはだたの機会損失になることがあります.
とにかくこちらで多くを語る必要はなく,まさに”まずは読んでください”に尽きる本当の意味での必読書です.
エンジニアとしてでなく,少しでもコードに触れる機会のある方は全員読むべきです.
slackbotでポケモンガチャ作った
Why
仕事はslackメインだし学生時代の研究室メンバーと今もslackでやりとりするようになりました.
ていうか卒業したら大学のOBOGのワークスペースに強制収容され,遊び道具にも使うようになったからbot活用していきたくなりました.
そもそも会社で治安の悪いslackスタンプMEGAMOJIが横行していたので,スタンプ作って遊んでいたらポケモンスタンプ見つけてしまいました.
ポケモンは小学生のときにキモオタして以来なので,記憶は金銀あたりで止まっています.
でも最近暑くて虫取り少年スタイルで出勤しているせいか,ポケモンゲットしたくなりました(夏バテ).
詳しい導入方法は以下を参考にしました.
qiita.com
What
適当にポケモンとか投稿するとこうなりたい.

slackbotガチャは下のようなワークスペースのカスタマイズ画面で簡単に設定できます.ガチャ結果(おみくじ結果)は「slackbotの返信」に入力します.

スタンプ名は :pokemon: の形に整形して同様に入力すればいいのですが,ポケモンスタンプは何十個もあって相当だるい...のでPythonで文字列加工しました.
How
きっともっとスタイリッシュなやり方があるでしょうが,仕事の片手間でやった処理を紹介します.
こうしたらよかったやん,はコメントいただけると助かります.
1. スタンプ名の取得
普通にターミナルから ls コマンドでemojiディレクトリの中身みてみた.
➜ github.com git:(master) ✗ ls slack-emoji-pokemon/emojis abra.png electrode.png kingdra.png parasect.png sneasel.png aerodactyl.png elekid.png kingler.png persian.png snorlax.png aipom.png entei.png koffing.png phanpy.png snubbull.png alakazam.png espeon.png krabby.png pichu.png spearow.png ampharos.png exeggcute.png lanturn.png pidgeot.png spinarak.png ......
多分あと10倍くらいこの png ファイルの羅列が続く.
とりあえずこの羅列をコピペして txt ファイルに保存.
2. ファイルを読み出す
保存したスタンプ名ファイルpoke.txtを読み出す.
f = open("poke.txt", "r")
raw = f.read()
f.close()
3. 文字列の加工
読み出した文字列を加工し,変数pokelist にリストとして格納する.
このときファイル名を要素として取り出し,各要素の.pngが邪魔なので:の文字列で置換する.
pokelist = raw.replace('.png', ':').split()
変数pokelistの中身(一部)はこんな感じ.
['abra:', 'croconaw:', 'gastly:', 'jynx:', 'meowth:', 'pikachu:', 'seel:', 'togepi:', 'aerodactyl:', 'cubone:', .... 'pidgey:', 'seaking:', 'tentacruel:']
4. まだ文字列の加工
ゴールはこのカタチ:pokemon:なので,各要素の先頭の文字列に:と,最後に改行が必要.
新しくリストpokeを用意して格納する.
Pythonだと文字列連結が演算子でできる.
poke = []
for i in range(len(pokelist)):
poke.insert(i,':'+pokelist[i]+'\n')
5. ファイルに書き出す
文字列をそのままテキストファイルからコピペして「slackbotの返信」に貼り付けたい.
f = open('result_poke.txt', 'w')
f.writelines(poke)
f.close()
slackbotに登録
あとはresult_poke.txtというファイルが作成されているはずなのでこんな感じでslackbotに登録する.

まとめ
これで今後slackスタンプを一括大量追加しても,すぐガチャ作れます.
Pythonでそんなに難しい文字列処理することなくできました.
せっかくなのでPythonでslackbot作ろうと思います.
無題その1
おひさしぶりです.
最近連絡関係は会社から大学時代の友達にいたるまでslackで完結してしまうようになったよしたかです.
もうLINEで連絡してこないでください(違
冗談はさておき,とうとう学生生活を卒業し新卒というレッテルを貼られ社会進出してしまいました.
今年の春に上京し,某広告屋さんでwebエンジニアとして働きはじめました.
人生で今後もう受けることのないシンソツケンシュウや先輩エンジニアたちの出現に,学生時代と比べられないスピードで毎日を送っていました.
名刺交換や電話対応ゲキムズ(そもそも電話自体になぜか慌ててしまう習性が身についているのでニガテ).
総合職の同期たちはコミュ力おばけだらけ.
これまで機械学習系の論文を読んで数式に起こしてアァでもないコォでもないしてたので,技術研修ではweb系の知識少ないマンの自分はのびしろォ!
そんな感じであっという間の3ヶ月が経過しました.
最近やっと実務に入り,OJT制度のもと業務効率化を目的にしたwebアプリを開発しはじめました.
...とここまでみてきた景色を(相当ざっくり)かいつまんでみましたが,何が言いたいかというとアウトプット不足です.
こうして久しぶりにブログを更新しているのはとりあえずアウトプットしたかったというモチベーション.
ニガテな電話対応研修では,完結に言葉でまとめることが全くできなかった.
コミュ力おばけたちからは「伝える」と「伝わる」の違いを教わりました.
なによりweb初心者の自分はわからないことがわからない(コーディング初学).
そんなことを感じ,シンプルに文章化したり考えをまとめたりする時間がほぼなかったと痛感しました.
このブログ自体も備忘録目的で始めたつもりが最初の備忘録 - よしたかのぶろぐしかなくて草しか生えない.
もはや今書いていることも読者に伝わっている文章かどうかすら謎な気持ち.
ということでこんな拙すぎる記事ですが,今後は技術系に限らず些細な所感を駄文ながら残していこうと思います.
何年後かに読んだら恥ずかしく感じるんだろうなあ.
なまあたたかい気持ちで見守っていただけると幸いです.
以上,初心表明的なやつ.
最初の備忘録
today's trouble
備忘録,めちゃめちゃ大事だなと今更気付きましたこんにちは.
コンピュータサイエンスにおける知能系の研究が本分,新しいもの好きな性格から中途半端にサービスを利用しては飽きの繰り返しをしがちな東北の田舎で大学院生を生業とする者です.
初めて備忘録ブログ始めたわけですが,ブログ自体は高校生から,アメブロ→zozo→tumblr→hatenaという編纂で季節のようにネット上を移りゆく.というかそもそも備忘録なのにこんな自己紹介いるのって感じ.
追々備忘録などという形式に慣れていくつもりです,どうぞお手柔らかに.
cannot use pip3
よくpythonっていう蛇さんがロゴに可愛いくてライブラリが豊富でバズるプログラミング言語を研究で利用するのですが,生きた化石のように
➜ notebooks git:(master) ✗ python -V Python 2.7.11 :: Continuum Analytics, Inc.
で頑張っていました.こないだ後輩にバカにされました.アップグレードしました.minicondaで管理しています.
➜ notebooks git:(master) ✗ python3 -V Python 3.5.2
3系にしてから半年経った12月.知識処理特論という授業の課題でコーパスの文字種に対するエントロピーやバイト数を求めることになりました.開発環境はipython notebookです.起動しよう.
➜ notebooks git:(master) ✗ ipython3 notebook
[TerminalIPythonApp] WARNING | Subcommand `ipython notebook` is deprecated and will be removed in future versions.
[TerminalIPythonApp] WARNING | You likely want to use `jupyter notebook` in the future
Traceback (most recent call last):
File "/usr/local/bin/ipython3", line 11, in <module>
sys.exit(start_ipython())
File "/usr/local/lib/python3.5/site-packages/IPython/__init__.py", line 119, in start_ipython
return launch_new_instance(argv=argv, **kwargs)
File "/usr/local/lib/python3.5/site-packages/traitlets/config/application.py", line 657, in launch_instance
app.initialize(argv)
File "<decorator-gen-109>", line 2, in initialize
File "/usr/local/lib/python3.5/site-packages/traitlets/config/application.py", line 87, in catch_config_error
return method(app, *args, **kwargs)
File "/usr/local/lib/python3.5/site-packages/IPython/terminal/ipapp.py", line 300, in initialize
super(TerminalIPythonApp, self).initialize(argv)
File "<decorator-gen-7>", line 2, in initialize
File "/usr/local/lib/python3.5/site-packages/traitlets/config/application.py", line 87, in catch_config_error
return method(app, *args, **kwargs)
File "/usr/local/lib/python3.5/site-packages/IPython/core/application.py", line 446, in initialize
self.parse_command_line(argv)
File "/usr/local/lib/python3.5/site-packages/IPython/terminal/ipapp.py", line 295, in parse_command_line
return super(TerminalIPythonApp, self).parse_command_line(argv)
File "<decorator-gen-4>", line 2, in parse_command_line
File "/usr/local/lib/python3.5/site-packages/traitlets/config/application.py", line 87, in catch_config_error
return method(app, *args, **kwargs)
File "/usr/local/lib/python3.5/site-packages/traitlets/config/application.py", line 514, in parse_command_line
return self.initialize_subcommand(subc, subargv)
File "/usr/local/lib/python3.5/site-packages/IPython/core/application.py", line 236, in initialize_subcommand
return super(BaseIPythonApplication, self).initialize_subcommand(subc, argv)
File "<decorator-gen-3>", line 2, in initialize_subcommand
File "/usr/local/lib/python3.5/site-packages/traitlets/config/application.py", line 87, in catch_config_error
return method(app, *args, **kwargs)
File "/usr/local/lib/python3.5/site-packages/traitlets/config/application.py", line 445, in initialize_subcommand
subapp = import_item(subapp)
File "/usr/local/lib/python3.5/site-packages/ipython_genutils/importstring.py", line 31, in import_item
module = __import__(package, fromlist=[obj])
ImportError: No module named 'notebook'
!???????????
どうやら3系にあげてから僕はpythonと仲良くなれてなかったみたい.まだ生きた化石だった.
というわけでリファレンスあさりスタート.
以下を参照します.
pipコマンドでPython2、pip3コマンドでPython3が使われるようにしたい-stackoverflow
https://github.com/yyuu/pyenv#installation
➜ notebooks git:(master) ✗ pip install --upgrade pip equirement already up-to-date: pip in /Users/yoshidatakayuki/miniconda2/lib/python2.7/site-packages
続いて,i wanna install pip3.
“➜ notebooks git:(master) ✗ pip3 -V pip 8.1.2 from /usr/local/lib/python3.5/site-packages (python 3.5)”
……installed
next,i try to run “pip3”
(➜pip3 install requests) . . . 100% |████████████████████████████████| 583kB 549kB/s Installing collected packages: requests Successfully installed requests-2.12.3 You are using pip version 8.1.2, however version 9.0.1 is available. You should consider upgrading via the 'pip install --upgrade pip' command. ➜ notebooks git:(master) ✗
whats 'pip install --upgrade pip’ ?
➜ notebooks git:(master) ✗ pip install --upgrade pip Requirement already up-to-date: pip in /Users/yoshidatakayuki/miniconda2/lib/python2.7/site-packages
……ignore,haha
一旦こちらも無視します.
pip3’s libraryを確認します.
➜ notebooks git:(master) ✗ pip3 list appnope (0.1.0) decorator (4.0.10) ipython (5.1.0) ipython-genutils (0.1.0) Jinja2 (2.8) MarkupSafe (0.23) numpy (1.11.2) pexpect (4.2.1) pickleshare (0.7.4) pip (8.1.2) prompt-toolkit (1.0.9) ptyprocess (0.5.1) Pygments (2.1.3) pyzmq (16.0.2) requests (2.12.3) setuptools (28.7.1) simplegeneric (0.8.1) six (1.10.0) tornado (4.4.2) traitlets (4.3.1) wcwidth (0.1.7) wheel (0.29.0) You are using pip version 8.1.2, however version 9.0.1 is available. You should consider upgrading via the 'pip install --upgrade pip' command.
oh,there not exist ipython!
続いて以下のブログを参照しました.
nsbioの備忘録
“you must install jupyter when cannot run ‘ipython notebook’.”
stack overflow says same message.
“ notebooks git:(master) ✗ ipython3 notebook [TerminalIPythonApp] WARNING | Subcommand `ipython notebook` is deprecated and will be removed in future versions. [TerminalIPythonApp] WARNING | You likely want to use `jupyter notebook` in the future [I 13:11:56.681 NotebookApp] Serving notebooks from local directory: /Users/yoshidatakayuki/gitrepository/workspace/notebooks [I 13:11:56.681 NotebookApp] 0 active kernels . . . . ”
ふぅ...無理やり感でなんとか復旧....
はてなで備忘録の書き方も覚えて行こう!